Karim
Abdel Sadek
 Berlin :)
Berlin :)
PhD Student in Computer Science at UC Berkeley
karimabdel at berkeley dot edu
About Me
Hi, I'm Karim! I am a first year CS PhD student at UC Berkeley. I am lucky to be advised by Stuart Russell and to be part of CHAI and BAIR. My work is partially supported by the Cooperative AI PhD Fellowship.
Before starting my PhD, I spent time at the Center for Human-Compatible AI and at the Krueger AI Safety Lab, University of Cambridge, where I was fortunate to be supervised by Michael Dennis, Micah Carroll and David Krueger.
I completed my MSc in AI at the University of Amsterdam in 2025. Before my MSc, I graduated with a BSc in Mathematics and Computer Science at Bocconi University. I was fortunate to be advised by Marek Eliáš, working on online learning. During my BSc, I spent the Spring '23 semester at Georgia Tech, supported with a full-ride scholarship.
Please reach out if you are interested in my research, you want to have a quick chat, or anything else! You can e-mail me at karimabdel at berkeley dot edu.
Research
I am broadly interested in Reinforcement Learning, Cooperative AI, and AI Safety. My research style is a mix of both theory and practice, with the goal of designing methods which are both well-founded and that have the potential to scale empirically. Recently, I have been mostly excited about designing better ways to do inverse RL and preference learning, understanding generalization in RL and modern AI systems, and in more foundational topics in RL theory and game theory.
News
- May 26, 2025 I received the Cooperative AI PhD Fellowship!
- Jan 07, 2025 Our paper "Mitigating Goal Misgeneralization via Minimax Regret" was accepted at RLC 2025 in Edmonton!
- Jul 01, 2024 I started work on Goal Misgeneralization in RL at the Krueger AI Safety Lab, University of Cambridge, supported by an ERA Fellowship.
- Jan 15, 2024 My first paper "Algorithms for Caching and MTS with reduced number of predictions" was accepted at ICLR with scores 8,8,8,8!
Selected Publications
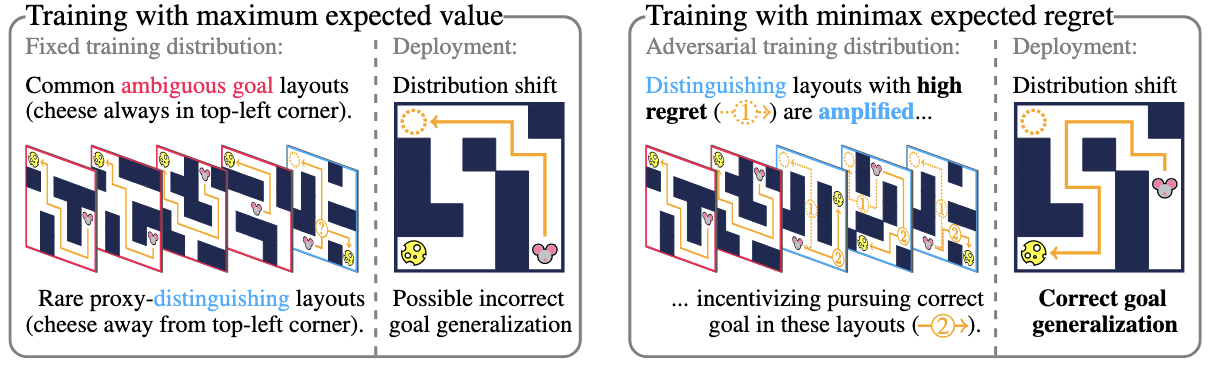
Mitigating Goal Misgeneralization via Minimax Regret
RLC 2025
TL;DR: We use minimax regret to train RL agents that are robust to goal misgeneralization.
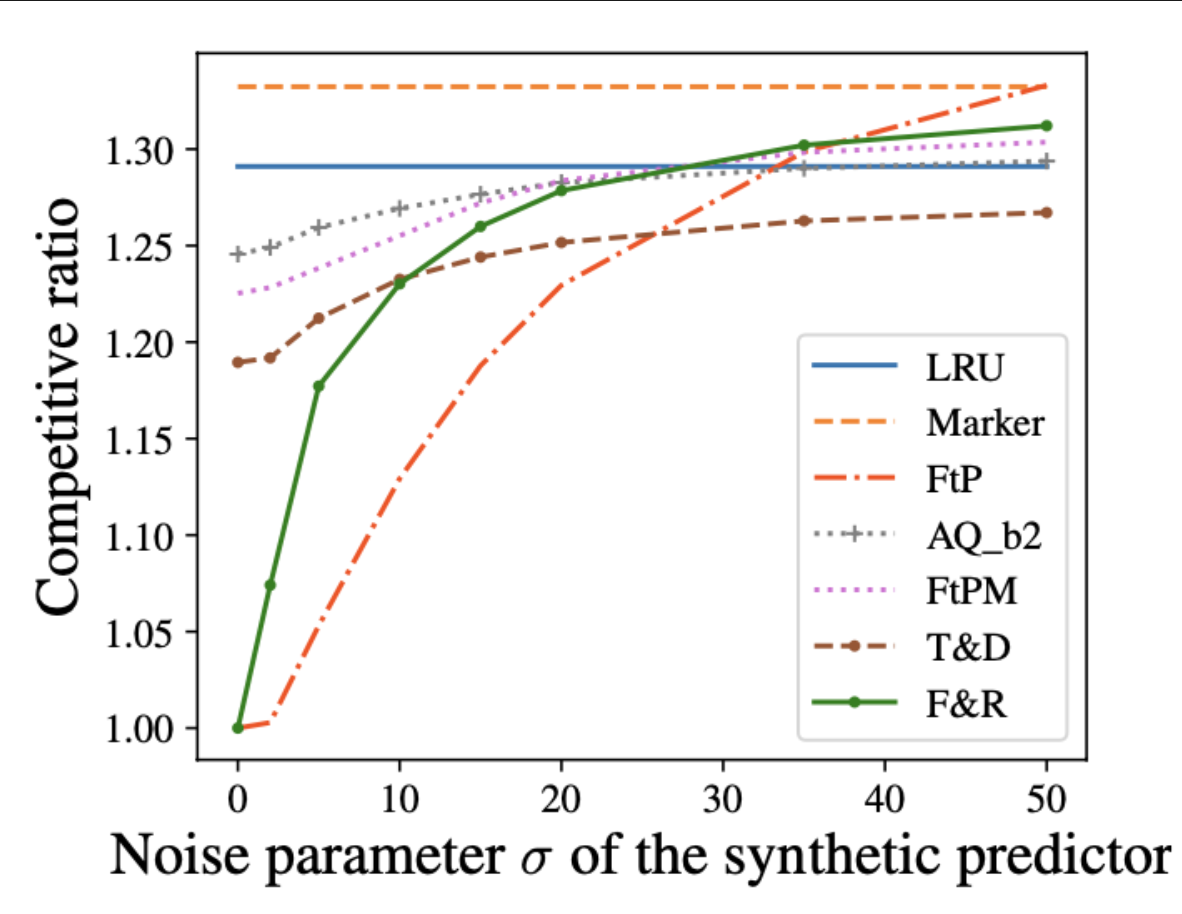
Algorithms for Caching and MTS with reduced number of predictions
ICLR 2024
TL;DR: We design online algorithms that achieve optimal consistency-robustness tradeoffs using only a reduced number of predictions.